
trained on Hypersim

trained on ScanNet
In previous articles, we have introduced the concept of Diminished Reality (DR). In short, DR conceals a real object in the scene by replacing it with background information in order to give the viewer the illusion, that the object is no longer present. This is useful to avoid that it conflicts with object inserted into the scene in place of the original object. But the questions are: How do we select the object to be removed, without asking the user to draw a mask? And how do we update the selection when the user moves?
We have introduced the concepts behind Instance Segmentation in a previous article. Given an image of the scene (which could also be a panoramic image), the task is to provide a mask for each object instance (i.e., if we have two chairs overlapping in the image, we still want to separate masks) as well as a class label for each of these masks (e.g. “chair”).
One challenge for all machine learning tasks is the availability of training data. Basically, there are two choices: either data is captured with cameras and then annotated (for semantic indoor segmentation this applies for example to the Scannet and Matterport3D datasets, or data is generated synthetically (e.g., as one for InteriorNet, Structured3D or the recent Hypersim datasets). The first results in realistic data, but at the cost of creating annotations manually or semi-automatically of limited quality, while in the second case annotation come for free, but there is a domain gap between rendered scenes and real images.
Instance segmentation on panoramic images adds another challenge: panoramic training data is scarce, and thus it seems a better approach to train on regular data and ensure that the algorithm generalises to panoramic data. We have analysed this issue in a paper published in fall 2021.
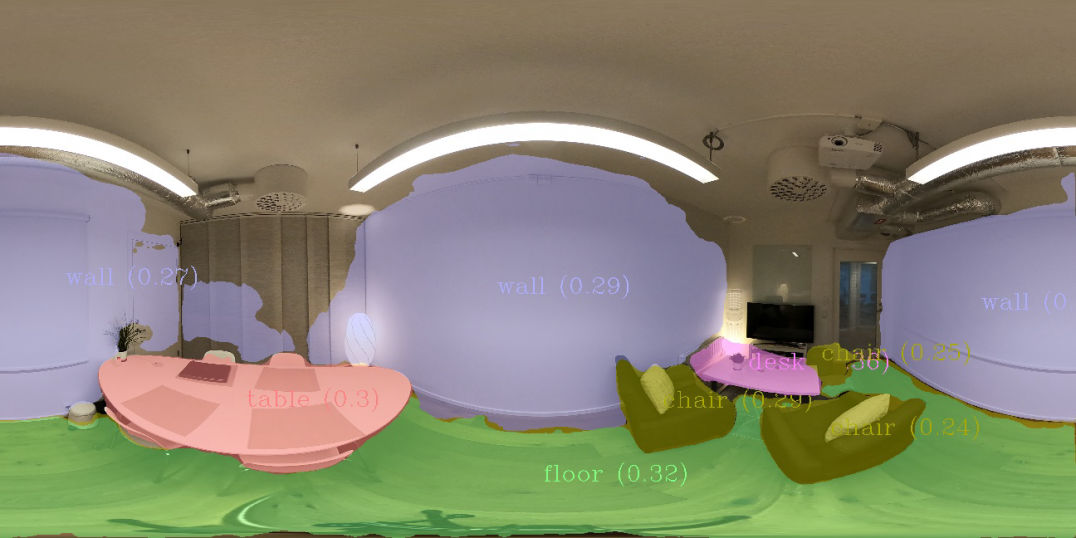
The figures below compares results of our SOLOv2 model, fine-tuned on either Scannet (left) and Hypersim (right). We see that the segmentation quality is better for the variant trained on Hypersim, in particular for the wall segments.
trained on Hypersim
trained on ScanNet
Dataset dependency
If we look at the datasets, we see that the images in the datasets have different fields of view, and the wider one generalises the better to panoramic data.

Hypersim sample

ScanNet sample
What can we do about the lack of appropriate training data? We can pretrain the network with a dataset that does not have exactly the same classes, but still includes information that helps adjusting the parameters of the model. COCO is a dataset containing common everyday object classes, including both indoor and outdoor images. Some of these classes are relevant for indoor scene understanding, while others are not. If we train the network on COCO, and then change the detection and segmentation heads of the network in order to adjust a new set of classes, and train these heads, we gain from the information in both datasets.
COCO-pretrained backbone

ScanNet only
Made with Mobirise html site templates