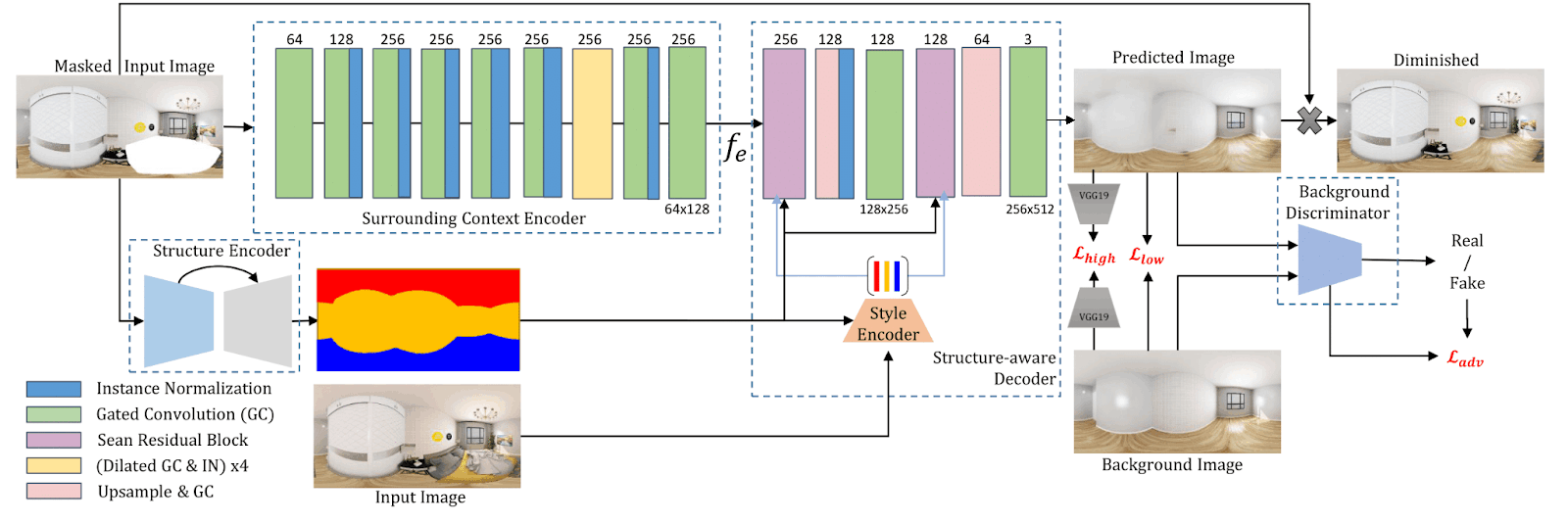
The PanoDR model that preserves the structural reality of the scene while counterfactually inpainting it. The input masked image is encoded twice, once densely by the structure encoder outputting a layout segmentation map, and once by the surrounding context encoder, capturing the scene’s context while taking the mask into account via a series of gated convolutions. These are then combined by the structure-aware decoder with a set of per layout component style codes that are extracted from the complete input image. The final diminished result is created via compositing the predicted and input images using the diminishing mask.
