
The Greek sea Bob is dreaming of
Many people, at some point in their life, start taking swimming lessons. For Bob, as for many other people, this means signing up to the local swimming club, buying a pair of goggles and getting into the pool with the help of an instructor. Lessons progress and sometime later they know how to swim. Equipped with excitement and a new skill, happily anticipate the spring break to jump into one of the Greek islands and practice.
The Greek sea Bob is dreaming of
Months passed by. Bob enjoys his smoothie on top of the deck as the ferry crosses Cyclades towards Santorini. Suddenly, sky turns grey. Temperature drops at an almost unbelievable rate and a gust of wind hammers the boat from the side! People gasp in amazement, Bob jumps to catch his glass brilliantly, right before falling-off the tip of the table, when yelling for help turned this charming adventure into drama.
“-Swimming, anyone??!!”, in Mediterranean-English was heard, as a woman screamed just right off the deck’s edge. The moment of truth! Bob takes a deep breath and sprints towards her, only to stare hesitantly, as the currents drag her little girl away from the vessel.
“-Com’ on!”, Bob shouted silently to himself, “-You’ve learnt how to do it in the pool; now, jump into the sea! ” or not…
It’s not all about buoyancy
On a bright shiny day, there wouldn’t be really that much of a difference. On this stormy afternoon though, it gets clear that his indoor heated swimming pool was never a great representative of reality. Can he thrust himself properly on high waves? Can he withstand the water temperature until real help arrives? Can he even keep his eyes open in salty water without his goggles? These, and many more, synthesize an ocean of possibilities for what we only know has little relevance to what Bob has been trained on. Waves in swimming pools are usually minuscule, water temperature is comforting and trainees always wear goggles. In the wild, on the other hand, waves can be anything from tiny to gigantic, waters can be freezing or boiling and people may need to submerge without equipment.
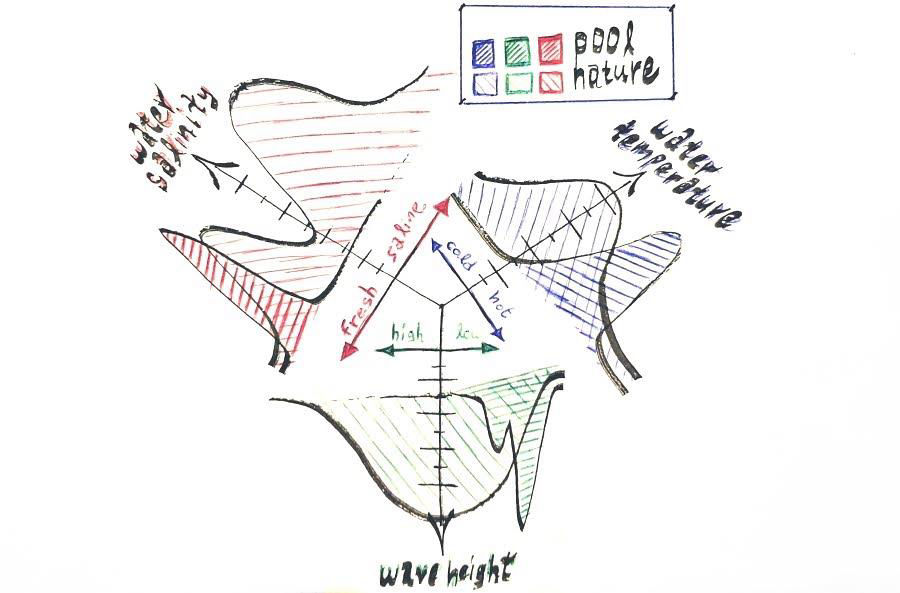
Challenges that Bob has to face in the wild sea
In other words, there is a d i s t r i b u t i o n s h i f t between conditions met in real-life and what Bob is trained on. He could be better trained; apply general solutions, like practice in the sea more often, or try to break down the concept and learn how to propel on high waves, practice in cold-water or condition his eyes with salty water to gradually get accustomed. But even then, it is not wise to try to mitigate all possible aggravating factors, without knowing for sure which ones are important and which are just fine to not deal with, and still succeed. Thus, it would be of great use to develop an experimental framework, a b e n c h m a r k , where each one of these factors could be reproduced independently and studied for its impact on performance in isolation or in combination with others.

Bob's ideal benchmark
In Bob’s case, that translates to creating a multitude of pools to test his performance, each one with all conditions similar to what he is accustomed apart from one, each time different, and then start making combinations to allow him study the phenomenon even deeper. In the end, he can apply his sought training techniques, measure their impact on mitigating each of the aggravating factors in isolation or combined, and finally get a vastly better picture of w h a t and w h y actually works. Our work aims to do exactly that in a challenging computer vision task;
Monocular 360° depth estimation

Depth prediction from panoramic images
Our task is to train a neural network to predict depth from panoramic color images. Note that this gets especially challenging due to the spherical distortion of such images.
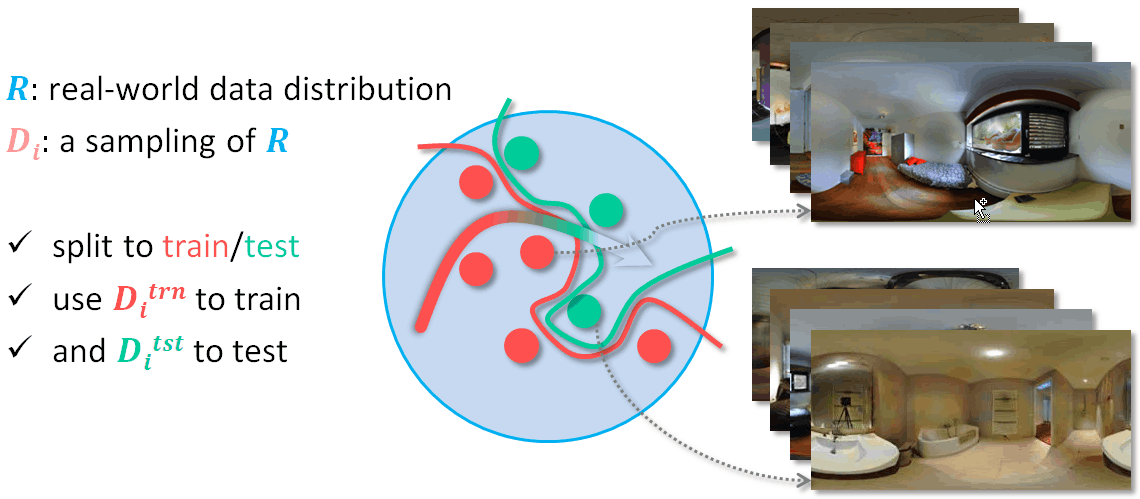
The most basic approach to training is to take some sampling of the real-world, for example a dataset of images like the Matterport3D [1], split it into two disjoint subsets, use one to train the model and the other to test its performance; all under the assumption that the test set is a good enough representative of real-world distribution. As we saw earlier, good performance in one sampling of the world does not guarantee generalization, as there may be significant distribution shift between this sampling and reality.
Lately, a new model-development scheme has been gaining traction. Instead of having train and test sets derive from the same sampling, a.k.a dataset, you use a totally different one to test, like for example the GibsonV2 [3], expecting it to exhibit some generalized distribution shift, enough to be a more reliable measure of real-world performance.
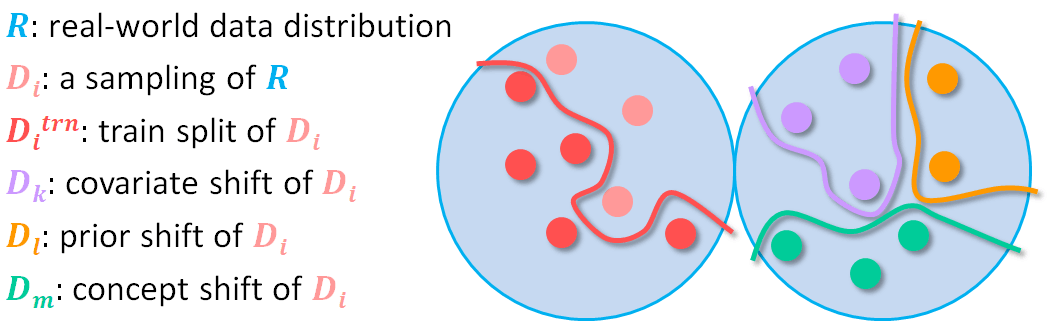
Our work differs by identifying three common modes of distribution shift in the task of monocular depth estimation, and introducing a scheme where multiple test-sets are used, each one expressing only some modes of it. This way, we can study their impact isolated from other factors and test generalized or targeted mitigation techniques for their performance, in a better-controlled environment.
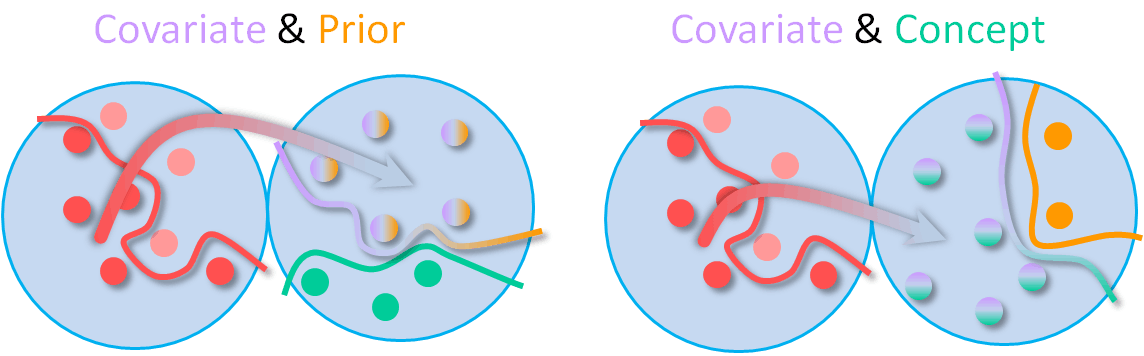
The three modes of distribution shift we study in our benchmark are: Covariate shift, which is a shift of the input domain, Prior shift, which is a shift of the output domain and Concept shift which is a shift of the relationship between input and output.
To train, we use the default M3D train-split which comprises scans of residential buildings.
To produce a test-set that expresses only covariate shift, we render the M3D test-split using Blender™’s filmic view transform, which alters color to produce a more cinematic look. Depth distribution and content-type remain untouched.

By analyzing the Gibson dataset, we identified that there is significant depth distribution shift between its tiny split and the default M3D test-set, thus if used can represent a zero-shot cross-dataset transfer with a prior shift. Input distribution and content-type are well preserved, as this split consists of residential-buildings as well and is rendered in the same way as M3D.
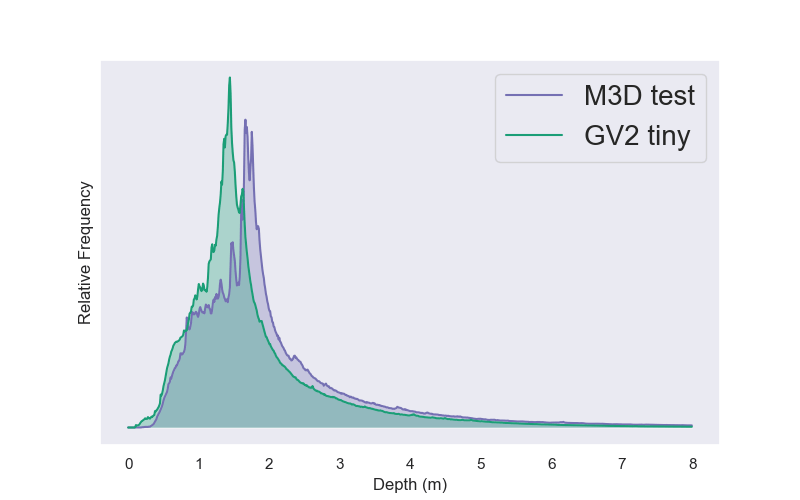
To present a set that exhibits concept shift only, we use Gibson fullplus split that includes non-residential buildings, like super-markets, under-construction buildings and garages. Depth distribution between it and M3D-test match, and input distribution is preserved by rendering it the same way.

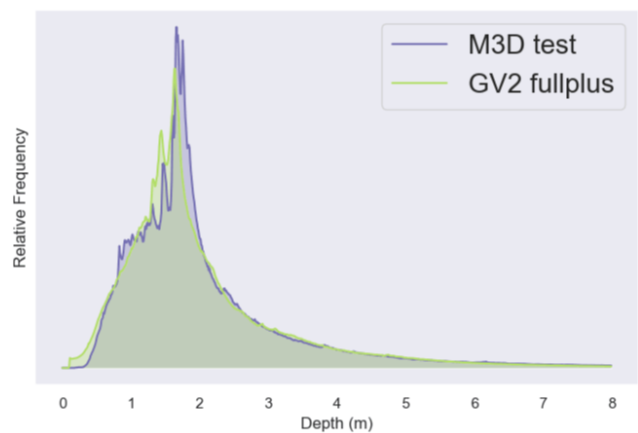
Exploiting the nature of rendering synthesis further, we can try to stack distribution shifts beginning from the covariate shift with the prior one, by rendering the Gibson tiny split with the filmic view transform.
Further, combine the covariate shift with the concept one, by rendering the Gibson fullplus split with the filmic view transform as well.
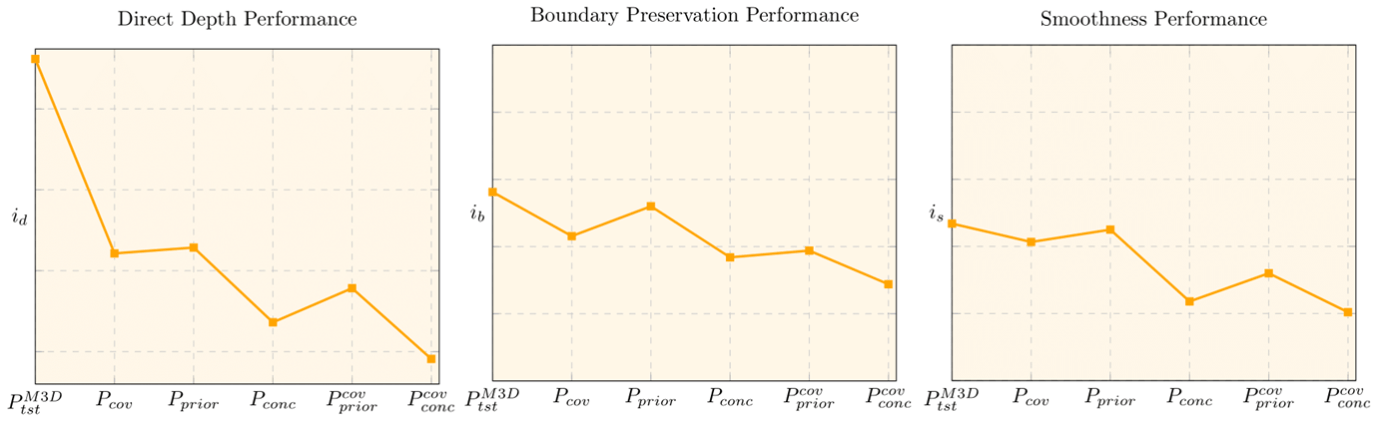
To understand the nature of these shifts in a quantitative way, we apply the benchmarking scheme for 360° depth estimation presented in Pano3D [4], evaluating the Unet baseline model. We rely on a set of complex indicators, aggregating metrics for depth estimation and its secondary traits, boundary preservation and smoothness, in a way that higher values are better.
As it is expected, all kinds of distribution shift seem to hurt the performance of the baseline model. Among the three tested, the more complex concept shift proved to be the hardest to overcome. As for the stackability of the shifts, it is definitely evident, hinting further to the highly challenging nature of generalized shifts.
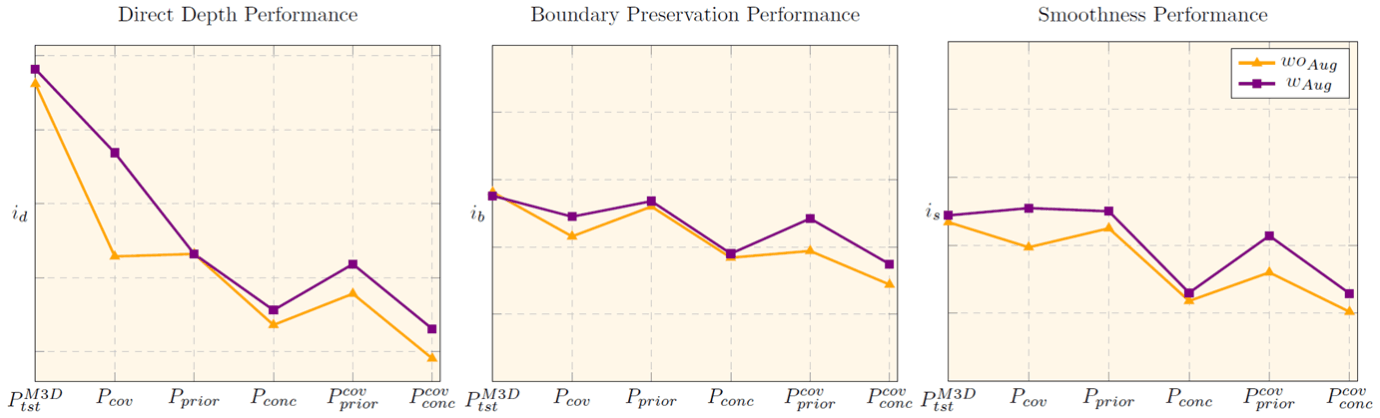
Going on with our analysis, we put to the test two common distribution shift-addressing techniques, to measure their alleviating capacity against our isolated shifts and their combinations, putting in dispute their conventional picture.
First, we train the aforementioned model with photometric augmentation. Experiments suggest that performance improves significantly when covariate shifts manifest, with the boost being higher when covariate shift is dealt in isolation but lower when it is mixed with others, further pointing to the complex nature of generalized shifts.
Lastly, we explore the effect of pre-training by using the Pano3D’s PNAS model, pre-trained on ImageNet. At first glance, it seems to offer substantial gains for the original test-set in raw depth estimation terms, and for the covariate shift in all terms. Interestingly thought, it seems that it does so only in isolation, as all combination-shifts proved to be quite challenging for it. Overall, it feels like the model only benefits from a higher quality parameter initialization, rather than gaining generalization capacity.
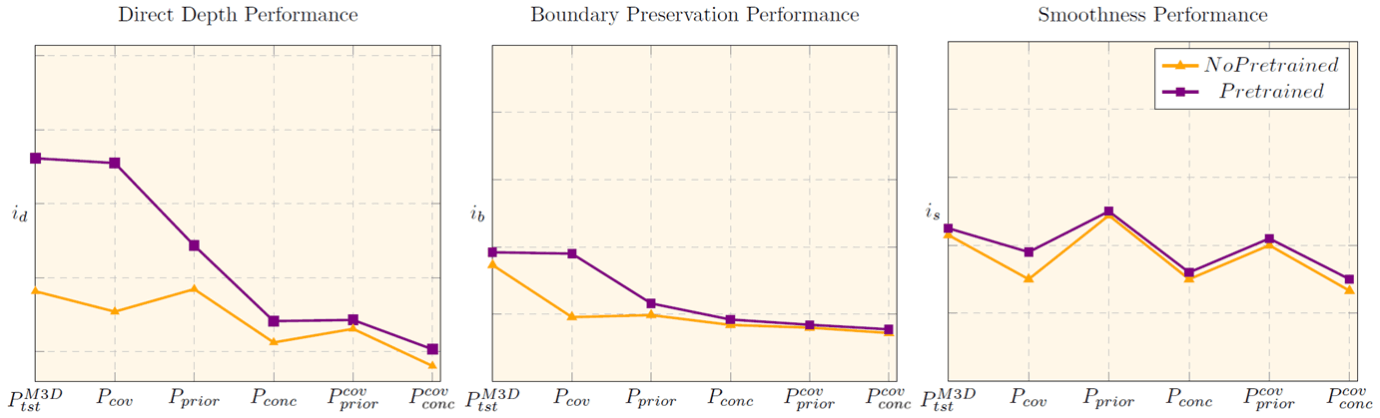
Taking into account the challenging and stackable nature of distribution shifts, we believe that our work facilitates future research by offering a structured methodology to address multiple shifts, where progress can be measured and correctly accounted for, as we transition into better generalized-shift addressing methods.
Ah yes, the girl…
She was finally rescued by the properly trained women and men of the coast-guard operating nearby. She lived happily ever after.
Mobirise page creator - Go here